-
[Pytorch] EMNIST CNN딥러닝 2020. 4. 3. 00:33

EMNIST Dataset EMNIST 데이터는 알파벳과 숫자로 이루어진 데이터입니다. 아래 사이트에 MNIST 데이터에 대한 설명이 잘되어 있습니다.
https://www.simonwenkel.com/2019/07/16/exploring-EMNIST.html
Exploring EMNIST - another MNIST-like dataset // SimonWenkel.com
MNIST is not part of my exploring less known datasets series. However, we will have a look at EMNIST. EMNIST [1] is another MNIST-like [2] dataset similar to Fashion-MNIST [3] and Kuzushiji-MNIST [4]. Contents Introduction Similar to other MNIST-like datas
www.simonwenkel.com
포스트에서는 알파벳 26개 문자만 분류하는 CNN모델을 만들어보겠습니다.
train_set = torchvision.datasets.EMNIST( root = './data/EMNIST', split = 'letters', train = True, download = True, transform = transfroms.Compose([ transfroms.ToTensor() # 데이터를 0에서 255까지 있는 값을 0에서 1사이 값으로 변환 ]) ) test_set = torchvision.datasets.EMNIST( root = './data/EMNIST', split = 'letters', train = False, download = True, transform = transfroms.Compose([ transfroms.ToTensor() # 데이터를 0에서 255까지 있는 값을 0에서 1사이 값으로 변환 ]) ) train_loader = torch.utils.data.DataLoader(train_set, batch_size=batch_size) test_loader = torch.utils.data.DataLoader(test_set, batch_size=batch_size)데이터를 다음과 같이 torchvision에서 로딩합니다. 이때 EMNSIT 에서는 split이라는 것을 지정하는데 위 사이트에 각각의 split에 대한 내용이 설명되어 있습니다. 알파벳 문자만 분류할 시 letters 라 하면 됩니다.
class NeuralNet(nn.Module): def __init__(self): super().__init__() self.layer1 = nn.Sequential( nn.Conv2d(in_channels=1, out_channels=10, kernel_size=3, stride=1, padding=1), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2) ) self.layer2 = nn.Sequential( nn.Conv2d(in_channels=10, out_channels=100, kernel_size=3, stride=1, padding=1), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2) ) self.dropout = nn.Dropout() self.fc1 = nn.Linear(in_features=100*7*7, out_features=1000) self.fc2 = nn.Linear(in_features=1000, out_features=26) def forward(self, x): x = self.layer1(x) x = self.layer2(x) x = x.reshape(x.size(0), -1) x = self.dropout(x) x = self.fc1(x) x = self.fc2(x) return xCNN 신경망을 정의합니다. 두개의 Convolution레이어로 되어 있으며 두개의 Linear 레이어를 가집니다. 이는 앞서 설명한 MNIST 예제에서 설명하였습니다.
learning_rate = 0.001 batch_size = 100 num_classes = 26 epochs = 3필요한 상수들을 지정합니다.
net = NeuralNet() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(net.parameters(), lr=learning_rate)Cross Entropy loss 함수를 이용해 loss를 측정할 것이고 Adam Optimizer을 사용하겠습니다.
pd_results = [] for epoch in range(epochs): for i, (images, labels) in enumerate(train_loader): out = net(images) loss = criterion(out, labels-1) optimizer.zero_grad() loss.backward() optimizer.step() total = labels.size(0) preds = torch.max(out.data, 1)[1] correct = (preds==labels-1).sum().item() if (i+1)%200==0: results = OrderedDict() results['epoch'] = epoch+1 results['idx'] = i+1 results['loss'] = loss.item() results['accuracy'] = 100.*correct/total pd_results.append(results) df = pd.DataFrame.from_dict(pd_results, orient='columns') clear_output(wait=True) display(df)학습을 시작합니다. 위와 같이 중간중간 프로세스를 Pandas를 이용해 출력합니다.
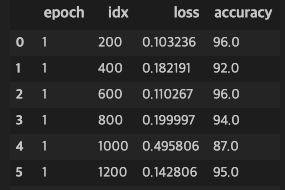
학습 결과 net.eval() correct, total = 0, 0 with torch.no_grad(): for i, (images, labels) in enumerate(test_loader): out = net(images) preds = torch.max(out.data, 1)[1] correct += (preds==labels-1).sum().item() total += len(labels) print("Test accuracy: ", 100.*correct/total)테스트를 진행합니다. 테스트 결과 정확도는 91.65%정도로 측정되었습니다.
'딥러닝' 카테고리의 다른 글
[Pytorch] MNIST CNN (0) 2020.03.31 [Pytorch] MNIST 신경망 구현 (0) 2020.03.28 [Pytorch] 간단한 신경망 구현 (0) 2020.03.16